Multi-modal Multi-channel Speech Separation
Authors: Rongzhi Gu, Shi-Xiong Zhang, Lianwu Chen, Yong Xu, Meng Yu, Yuexian Zou, Dong Yu
Abstract:
Target speech separation refers to extracting a target speaker's voice from overlapped audios of simultaneous talkers.
Previously the use of visual clue for target speech separation has shown great potentials.
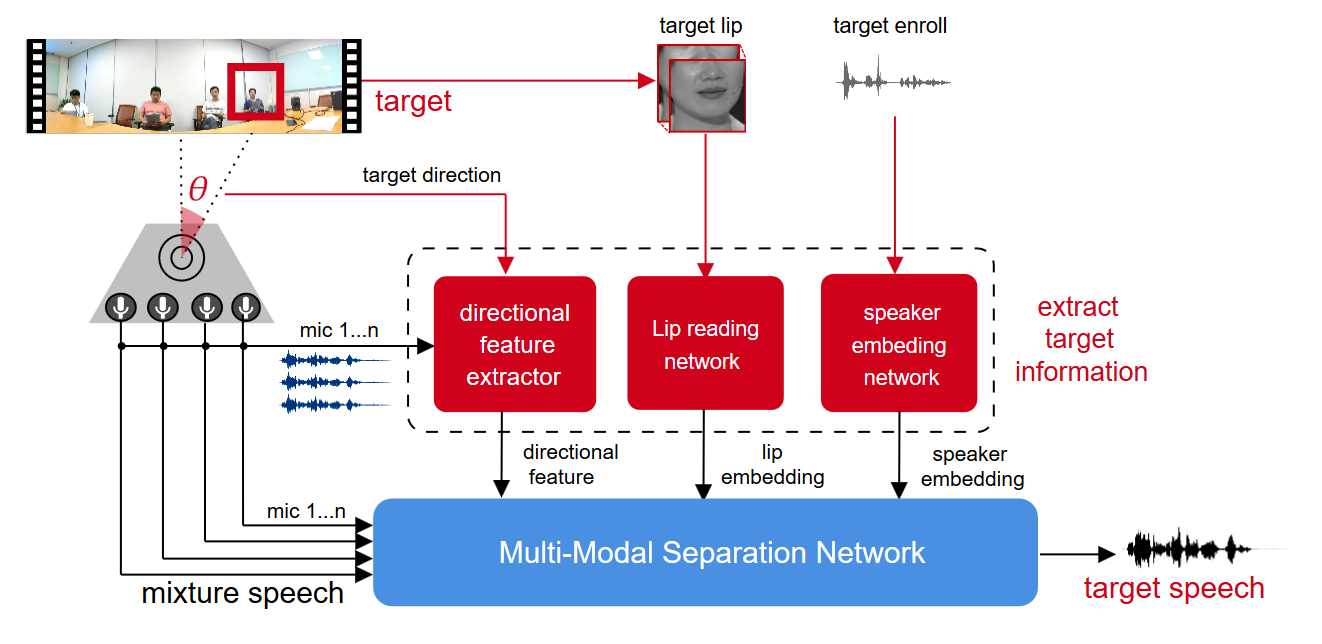
This paper extends it with a general multi-modal framework in the far-field scenario.
The framework leverages all the available information of target speaker, including his/her spatial location, voice characteristics and lip movements.
These target-related features are extracted and learned together with the separation task in an end-to-end neural architecture.
An important aspect of the multi-modal joint modeling is the form of fusion.
A factorized attention-based fusion method is proposed to aggregate different modalities.
To validate the robustness of proposed multi-modal system in practice, we evaluate it under different challenging conditions, such as one of the modalities is temporarily missing, invalid or noisy.
Experiments are carried out on a large-scale audio-visual dataset collected from YouTube and simulated into multichannels.
Evaluation results illustrate that our proposed multi-modal framework significantly outperforms single-modal speech separation approaches, even when the target's location or lip information is temporally missing or corrupted.